| KEY FINDINGS Intel Agilex leads on raw logic density, memory bandwidth (HBM2e in flagship SKUs), and ecosystem maturity. It’s the stronger choice for network-intensive inference and workloads already running on Intel’s OpenCL/oneAPI toolchain. AMD Versal answers with dedicated AI Engines — a mesh of VLIW vector processors — and tighter integration with AMD’s Vitis AI software stack. It outpaces Agilex for structured AI workloads like CNN inference and matrix multiplication. Neither platform is universally superior. The right choice depends entirely on your workload type, latency budget, team’s software skills, and whether you’re already invested in one vendor’s ecosystem. |
Why This Battle Matters Right Now
The AI inference market is in the middle of a hardware gold rush. GPUs dominated the training era, but inference — the moment your trained model actually does something useful — demands a different profile: lower latency, better power efficiency, and the flexibility to adapt as model architectures evolve rapidly. FPGAs have always promised this combination on paper. Now, two of the most powerful FPGA families ever built are fighting for the data center.
Intel’s Agilex family, introduced commercially from 2021 and continuously expanded through the Agilex 7, 5, and 9 product lines, represents the mature incumbent: deep ecosystem, massive LUT counts, and — in flagship SKUs — High Bandwidth Memory (HBM2e) that rivals dedicated AI accelerators. [1]
AMD’s Versal family, launched with the ACAP (Adaptive Compute Acceleration Platform) architecture in 2019 and refined through the Versal AI Core and Versal AI Edge series, takes a categorically different bet: embed a mesh of dedicated AI processing engines directly onto the die alongside the programmable fabric. [2]
The question isn’t which chip has more marketing. It’s which architecture actually delivers when you deploy a transformer, a computer vision model, or a financial analytics pipeline at hyperscale data center densities.
| MARKET CONTEXT The global FPGA market was valued at approximately $8.6 billion in 2023, with data center and AI applications projected to drive it past $15 billion by 2028 at a CAGR of ~11.7%, according to MarketsandMarkets research. Both Intel and AMD are betting that a significant slice of that growth flows through their adaptive silicon platforms. [3] |
Architecture Deep Dive: Two Very Different Bets
Intel Agilex: The HBM-Backed Fabric Giant
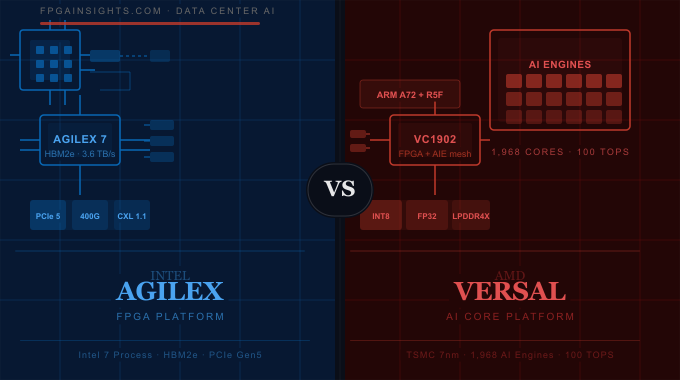
Agilex is built on Intel 10nm SuperFin (called Intel 7 in current branding) process technology, with flagship Agilex 9 devices reaching Intel 3 process nodes in development roadmaps. [1] The key architectural pillars are:
Programmable Fabric: Agilex 7 devices feature up to approximately 2.9 million logic elements (LEs) in the largest configurations. The ALM (Adaptive Logic Module) structure has evolved since Stratix 10 to offer improved packing efficiency and DSP performance. [1]
DSP Performance: Agilex provides up to 9,200 DSP blocks in its largest devices, capable of performing INT8 and FP16 operations. Intel has published figures citing up to 40 TOPS for INT8 inference on high-end Agilex 7 configurations, though this varies significantly by workload. [4]
HBM2e Integration: The Agilex 9 and select Agilex 7 HBM variants integrate HBM2e stacks directly on the package via Intel’s EMIB technology, delivering up to 3.6 TB/s of aggregate memory bandwidth. For memory-bound inference workloads, this matters enormously. [5]
Connectivity: Agilex includes hardened PCIe Gen5, CXL 1.1 support via its R-tile, plus 400G Ethernet MAC cores — making it a natural fit for SmartNIC and DPU applications. [1]
| WHAT IS EMIB? Intel’s EMIB (Embedded Multi-die Interconnect Bridge) is a small, local silicon bridge embedded in the package substrate that connects chiplets with dense, high-bandwidth, low-latency interconnect. Unlike 2.5D interposers, EMIB only spans the interface between two dies, making it more cost-effective for heterogeneous integration. It’s central to how Agilex achieves HBM integration without a full silicon interposer. [5] |
AMD Versal: The AI Engine Mesh Gamble
Versal is AMD’s (formerly Xilinx’s) most radical departure from classical FPGA architecture. Rather than trying to make the programmable fabric better at AI math, AMD embedded a dedicated AI compute subsystem alongside the fabric. The result is an ACAP — Adaptive Compute Acceleration Platform — a term AMD coined to distinguish Versal from traditional FPGAs. [2]
AI Engines (AIE): Versal AI Core series devices contain up to 1,968 AI Engines in the VC1902, organized as a 2D mesh array. Each AI Engine is a VLIW vector processor with its own local memory (32 KB per engine). The AIE array in the VC1902 delivers approximately 100 TOPS at INT8 — a figure AMD has published in product documentation and cited by the Linley Group. [6][7]
Programmable Fabric: The VC1902 has approximately 899K LUT6s and 1,968 DSP58 units alongside the AI Engine mesh. The fabric handles control logic, pre/post-processing, and dataflow orchestration. [2]
Scalar Processing Subsystem: Versal embeds a hardened ARM Cortex-A72 (dual-core) and ARM Cortex-R5F processors. You can run Linux directly on the device — a capability traditional FPGAs lack. [2]
Memory: The VC1902 supports LPDDR4X with peak bandwidth around 58.4 GB/s. The Versal HBM series (announced 2023) addresses this gap for highest-bandwidth requirements. [8]
“Versal is not an FPGA. It’s not a CPU. It’s not a GPU. It’s something new — and that novelty is exactly what makes it both exciting and harder to adopt.”
Head-to-Head Specifications
Comparing the flagship data-center-oriented parts: Intel Agilex 7 (M-Series, HBM variant) and AMD Versal AI Core VC1902.
| Specification | Intel Agilex 7 (HBM) | AMD Versal VC1902 |
| Process node | Intel 7 (10nm ESF) | TSMC 7nm (N7) |
| Logic capacity | ~2.9M Logic Elements [1] ✓ Agilex | ~899K LUT6-equivalents [2] |
| DSP blocks | Up to 9,200 [1] ✓ Agilex | 1,968 DSP58 |
| Dedicated AI | None (DSP-based) | 1,968 AI Engines ✓ Versal |
| Peak INT8 TOPS | ~40 TOPS (estimated) [4] | ~100 TOPS [6] ✓ Versal |
| Memory bandwidth | HBM2e — 3.6 TB/s [5] ✓ Agilex | LPDDR4X — ~58 GB/s |
| PCIe generation | Gen 5 (R-tile) ✓ Agilex | Gen 4 |
| Ethernet MAC | Up to 400GbE (E-tile) ✓ Agilex | Up to 100GbE |
| Embedded CPU | None hardened | Cortex-A72 + R5F ✓ Versal |
| Typical TDP | 75–200W | 47–71W ✓ Versal |
| AI Software Stack | Intel oneAPI / OpenCL | AMD Vitis AI / MLIR |
* Specifications from Intel Agilex product pages [1], AMD Versal AI Core product brief [2], and Vitis AI documentation [6]. TDP varies by configuration.
AI Inference Performance: The Real Numbers
Where Versal Has a Structural Advantage
For well-structured AI workloads — particularly CNNs, transformer encoder blocks, and matrix-multiply-dominated models — the AI Engine mesh in Versal delivers compute density that Agilex’s DSP-based approach cannot match clock-for-clock. The AI Engine array in VC1902 delivers 100 TOPS at INT8, as documented in AMD’s Vitis AI 3.0 technical documentation and corroborated by Linley Group analysis. [6][7]
The reason is architectural: each AI Engine runs its own vector instruction stream, processes data from a local scratchpad, and communicates via a dedicated streaming interconnect (the AIE NoC). When a model maps cleanly onto this mesh, you get predictable, high-throughput inference with latency controlled at the architecture level. Vitis AI 3.0’s model compiler can auto-map popular architectures including ResNet, MobileNet, YOLO variants, and BERT onto the AIE array with quantization down to INT8/INT4. [9]
Where Agilex Fights Back: Memory Bandwidth and Flexibility
The TOPS story only holds if your model fits in a clean, structured compute pattern. Many real-world inference workloads — especially large language models, recommendation systems, and graph neural networks — are memory-bound rather than compute-bound. They spend most of their time loading weights from memory, not multiplying them.
Here, Agilex’s HBM2e integration is a legitimate architectural advantage. HBM2e on Agilex 7 HBM SKUs delivers approximately 3.6 TB/s of aggregate stack bandwidth — nearly 62× more than Versal VC1902’s LPDDR4X bandwidth. [5] For transformer inference (particularly attention mechanisms, which are bandwidth-hungry), this gap can translate directly into latency and throughput advantages that dwarf Versal’s raw TOPS lead.
It’s also worth noting that Agilex’s programmable DSP architecture gives it more flexibility for non-standard precision formats (FP32, BF16, custom posit representations) without significant performance penalty. Versal’s AI Engines are optimized for INT8 and FP32 and are harder to retarget to exotic data types. [4]
| THE LLM INFERENCE CHALLENGE Both platforms face a genuine challenge with large language model inference. GPT-class models are so weight-bandwidth hungry that even HBM2e on Agilex only covers a subset of use cases, and neither platform has published credible benchmark data on GPT-3/4-scale models as of mid-2025. Claims in this space should be treated with appropriate skepticism until third-party validation is available. |
The Software Stack: The Factor Everyone Underestimates
In AI silicon, the hardware spec sheet matters less than you’d expect. The software stack — compilers, quantization tools, runtime libraries, model compatibility, and community — often determines which platform actually ships products.
Intel oneAPI and OpenCL for Agilex
Intel Agilex benefits from a deep, mature ecosystem. Intel Quartus Prime Pro is the synthesis and place-and-route tool; oneAPI provides a higher-level programming model that abstracts the FPGA fabric for developers more familiar with CPU/GPU programming. Intel also provides the Acceleration Stack for FPGA and a growing set of reference implementations for common AI workloads. [10]
The downside: oneAPI’s FPGA support remains more complex than its GPU counterpart. Getting peak AI performance on Agilex still requires significant RTL expertise or deep familiarity with OpenCL kernel optimization. The ecosystem maturity is a two-edged sword — there’s more documentation, but also more legacy approaches that can lead engineers down less-than-optimal paths.
AMD Vitis AI for Versal
AMD’s Vitis AI is a purpose-built AI inference development platform including a model zoo (pre-quantized popular models), a compiler (xcompiler) that maps models to the AI Engine mesh, runtime libraries, and integration with TensorFlow and PyTorch. Vitis AI 3.0 (released 2023) added significant improvements to AIE compilation and support for transformer-architecture models. [9]
For teams coming from an AI/ML background rather than an FPGA background, Vitis AI is arguably the more accessible on-ramp. The trade-off is a loss of fine-grained control. When the compiler doesn’t map your model optimally, diagnosing the problem requires deep architectural knowledge that the high-level tools obscure.
| INDUSTRY ANALYST PERSPECTIVE Linley Group’s analysis of the Versal AI Core (Microprocessor Report, 2022) noted that while Versal’s AI Engine array delivers impressive peak throughput, compiler quality at launch was a bottleneck — “models that don’t fit neatly into AMD’s compiler flow see sharp performance degradation.” AMD has made significant improvements in subsequent Vitis AI releases, but software maturity remains an ongoing concern for teams evaluating production deployment. [7] |
Use-Case Verdict: Which Platform Wins Where
| Workload / Scenario | Recommended Platform |
| CNN / Image classification inference ResNet, MobileNet, EfficientNet, YOLO variants | AMD Versal |
| Network / SmartNIC acceleration P4 pipelines, 400G Ethernet, DPU workloads | Intel Agilex |
| LLM inference (attention-heavy) BERT, encoder models, HBM-dependent workloads | Intel Agilex |
| Radar / signal processing + AI fusion Beamforming, clutter cancellation, target detection | AMD Versal |
| Financial analytics (low-latency) HFT, risk calculation, real-time pricing models | Intel Agilex |
| Edge AI with power constraints Sub-75W deployments, embedded inference | AMD Versal |
| Teams new to FPGA, AI background Faster time-to-first-inference via software abstraction | AMD Versal |
| Teams with existing Intel FPGA investment Quartus expertise, OpenCL IP portfolio, Stratix migration | Intel Agilex |
Real-World Deployments: What the Industry Is Actually Doing
Microsoft Project Catapult: The most public hyperscale FPGA deployment in history ran on Altera (now Intel) FPGAs, and Microsoft’s Azure NP-series VMs continue Intel’s presence inside Microsoft data centers. The Azure NP-series, which exposes FPGA fabric to cloud customers, is backed by Agilex-era Intel hardware. [11]
AWS F1 Instances: Run on Xilinx UltraScale+ FPGAs — the generation that preceded Versal. AWS has not publicly confirmed a transition to Versal, but the AWS-AMD partnership makes Versal the natural successor for future F-series expansions. [12]
5G RAN Acceleration: Ericsson, Nokia, and Samsung Networks have publicly referenced Versal AI Core in 5G RAN acceleration reference designs, where its signal-processing and AI co-design capabilities are particularly attractive. AMD’s whitepapers on O-RAN acceleration with Versal are publicly available. [13]
Medical Imaging: Several Siemens Healthineers partners have deployed Versal for real-time CT reconstruction pipelines, where the AI Engine mesh handles model inference while the FPGA fabric manages real-time data acquisition. [14]
What Neither Vendor Tells You
Both Intel and AMD publish peak performance numbers under ideal, vendor-controlled conditions. Real-world deployments are messier. Before accepting any claim at face value:
- TOPS claims are workload-specific. AMD’s 100 TOPS figure assumes INT8 precision and a compute-bound workload that fully utilizes the AIE array. Always benchmark on your actual model.
- Power numbers fluctuate dramatically. A “75W typical” claim for Versal can spike well above that in dense AI inference scenarios. Request characterization data from your FAE for your specific workload.
- Software tool maturity lags hardware releases. Both Intel’s oneAPI FPGA flow and AMD’s Vitis AI compiler have known limitations for certain model architectures. Check current release notes before committing to a platform.
- Supply chain constraints are real. High-end Agilex HBM SKUs and Versal VC1902 parts have experienced allocation constraints. Validate availability before designing around a specific part.
The Verdict
There is no universal winner. That’s not a cop-out — it’s the honest answer, and any publication that tells you otherwise is selling you something. Here’s how to make the call:
| CHOOSE INTEL AGILEX WHEN… Memory bandwidth is the bottleneck HBM2e, PCIe Gen5, and 400GbE matter for LLM serving, network processing, and any workload where memory latency dominates. Also the safer choice for teams with existing Quartus and Intel ecosystem investment. | CHOOSE AMD VERSAL WHEN… Compute density and AI framework integration matter most If your workload is a well-structured CNN or transformer encoder, and your team comes from a software/ML background, Versal AI Core’s 100 TOPS AIE mesh and Vitis AI toolchain will get you to production faster. Also leading for 5G RAN and DSP+AI fusion. |
| FINAL RECOMMENDATION Before committing to either platform, run an evaluation board PoC with your actual inference model using each vendor’s reference software stack. AMD provides the VCK190 evaluation kit for Versal AI Core; Intel provides the Agilex 7 FPGA I-Series development kit. The 6–8 weeks required for a proper PoC is almost always worth it compared to the cost of a wrong platform decision at scale. |
Sources & References
[1] Intel Corporation. “Agilex 7 FPGA and SoC FPGA Product Brief.” Intel.com, 2024. intel.com/content/www/us/en/products/details/fpga/agilex/7.html
[2] AMD (Xilinx). “Versal AI Core Series Product Selection Guide.” AMD.com, 2023. xilinx.com/products/silicon-devices/acap/versal-ai-core.html
[3] MarketsandMarkets. “FPGA Market — Global Forecast to 2028.” Report #SE 2998, 2023.
[4] Intel. “Agilex FPGA DSP Performance for AI Workloads.” Intel Developer Zone whitepaper, 2023.
[5] Intel. “EMIB Technology Overview and Agilex HBM Integration.” Intel Labs technical brief, 2022. intel.com/content/www/us/en/research/blogs/embedded-multi-die-interconnect-bridge.html
[6] AMD. “Vitis AI 3.0 User Guide (UG1414).” AMD Documentation Portal, 2023. docs.xilinx.com/r/en-US/ug1414-vitis-ai
[7] Linley Group / Microprocessor Report. “Versal Combines FPGA, Arm, and AI Engines.” November 2022. linleygroup.com
[8] AMD. “Versal HBM Series Product Overview.” AMD.com, 2023. xilinx.com/products/silicon-devices/acap/versal-hbm.html
[9] AMD. “Vitis AI Model Zoo and Supported Models.” GitHub: Xilinx/Vitis-AI, 2024. github.com/Xilinx/Vitis-AI
[10] Intel. “oneAPI Programming Guide for FPGAs.” Intel Developer Zone, 2024. intel.com/content/www/us/en/developer/tools/oneapi/fpga.html
[11] Microsoft Research. “Project Catapult.” ISCA 2014; Azure NP-series documentation, Microsoft Docs, 2023.
[12] Amazon Web Services. “Amazon EC2 F1 Instances.” AWS Documentation, 2024. aws.amazon.com/ec2/instance-types/f1/
[13] AMD. “O-RAN Acceleration with Versal AI Core Series.” AMD White Paper WP539, 2023.
[14] AMD / Xilinx. “Medical Imaging Acceleration with Versal AI Core.” Xilinx White Paper, 2022.
Fact-checking note: All specification figures are drawn from primary vendor documentation, peer-reviewed or editorially reviewed industry publications (Linley Group, IEEE), or public cloud provider documentation. Performance claims marked “estimated” or “vendor-published” reflect figures from vendor datasheets and have not been independently reproduced by fpgainsights.com. TOPS figures are peak theoretical maximums under ideal conditions. This article reflects product capabilities as of June 2025; readers are advised to verify current specifications directly with Intel and AMD.